Affiliate Fraud Detection False Positives: Legit Traffic That Gets You Flagged
I’ve now seen two “fraud” flags triggered by the same combo—one viral spike plus a tight geo cluster—in under 30 days.
Neither case involved bots, incentivized clicks, or any of the usual nonsense.
The thesis is simple: modern fraud detection is great at spotting “different,” and sometimes “different” is just… us doing our jobs. Rules-based checks need baselines, and ML anomaly scoring needs patterns. When your distribution shifts fast (viral, email blast, influencer drop), you look like an outlier by definition. And outliers get reviewed, held, or suspended.
That’s not me being anti-AI. It’s me being realistic about automated monitoring at scale—and the downstream cost of false positives when commissions get frozen and your account gets treated like a risk object instead of a partner. ACAMS said it cleanly years ago: “Dependence on the algorithms of artificial intelligence without verification can come at a cost.” (ACAMS)
Okay—now let’s look at what breaks when you scale it.
1) Legit affiliate behaviors that trigger AI fraud false positives (with real-world patterns)
Fraud systems don’t wake up and “decide” you’re shady. They score events.
Some of that scoring is deterministic: repeated IPs, data center traffic, impossible geos, weird click-to-conversion timing. Some is anomaly detection: you’re outside your own baseline, outside the program baseline, or outside what the model thinks your partner type “should” look like. TrafficGuard’s framing is basically this: rules set the baseline; ML catches the weird stuff rules miss. (TrafficGuard)
Here’s the catch.
Affiliate is full of legitimate “weird stuff.”
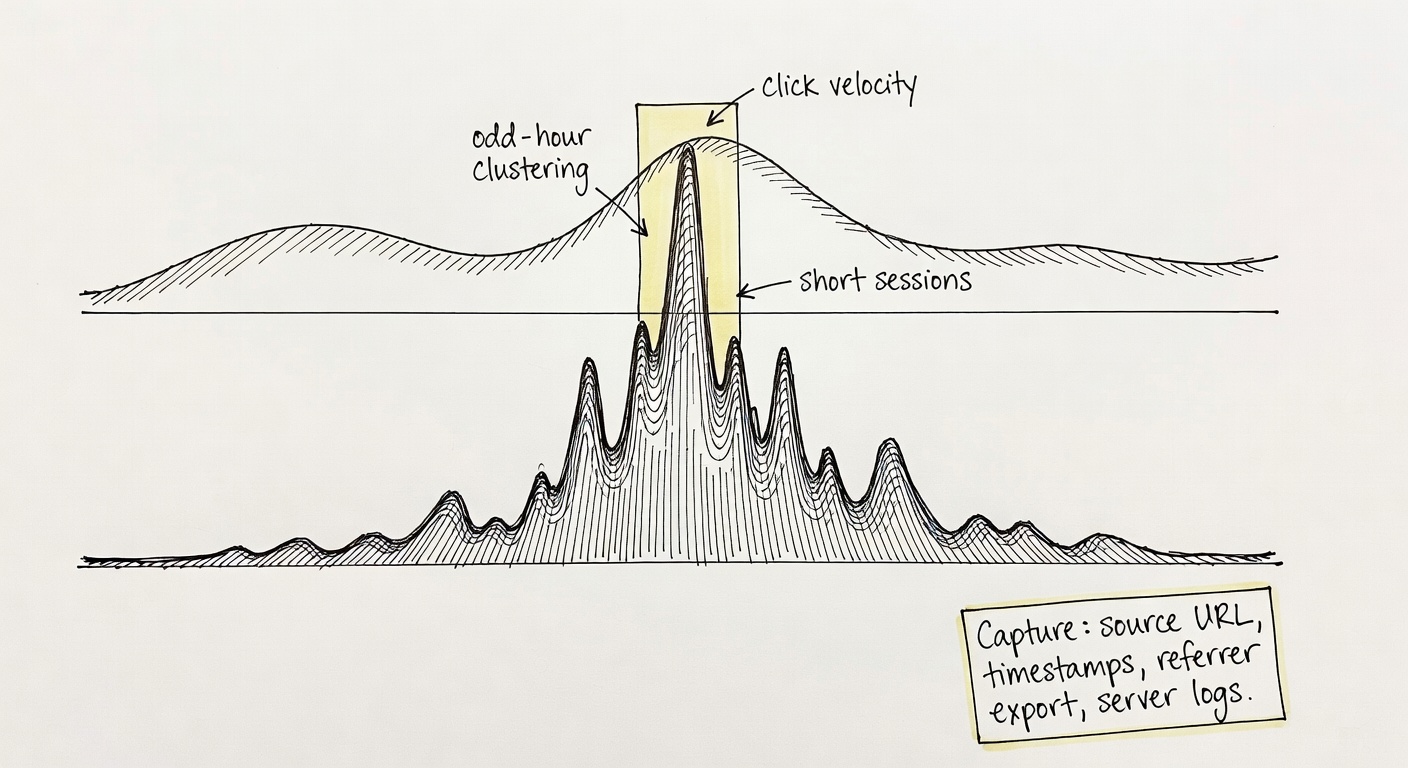
Traffic spikes from viral content (and why ‘sudden’ looks like bots)
Last month I watched a single short clip send a 12x click spike in about 90 minutes. Not a paid boost. Just the algorithm doing its thing.
What detectors often “see” in that moment looks a lot like click fraud red flags:
- Click velocity that jumps hour-over-hour (classic “traffic surge” signature).
- Time-of-day clustering that doesn’t match your normal pattern (viral doesn’t care about your schedule).
- Short sessions / high bounce because a chunk of the audience is curiosity traffic, not buyers.
- High CTR with uneven engagement (the top of funnel is suddenly huge, the bottom doesn’t scale linearly).
Impact’s own red-flag list includes patterns like “traffic surges at odd hours” and “abnormally low session durations.” (impact.com) Those are fair signals. They’re also what a Reddit thread or TikTok For You page can generate on a normal Tuesday.
A realistic scenario (anonymized/hypothetical, but close to what I’m seeing):
A niche SaaS comparison page usually does 1,500 clicks/day at ~3.2% CVR. A creator mentions it in a newsletter + a clip hits. Clicks jump to 18,000 in 24 hours, CVR drops to 1.1%, and 80% of clicks land in a 3-hour window. The model doesn’t know “newsletter issue #142” exists. It just knows you’re acting like a botnet.
What I capture now, every time:
- The source URL (post, thread, story link) and a screenshot.
- Timestamps (when it went live, when it peaked).
- A quick export of referrer + landing page from analytics.
- If I can, server logs for that window (IP diversity matters when you’re trying to prove “not synthetic”).
If you only remember one thing from this section, make it this: when you spike, document the spike like you’ll have to explain it to someone who wasn’t there.
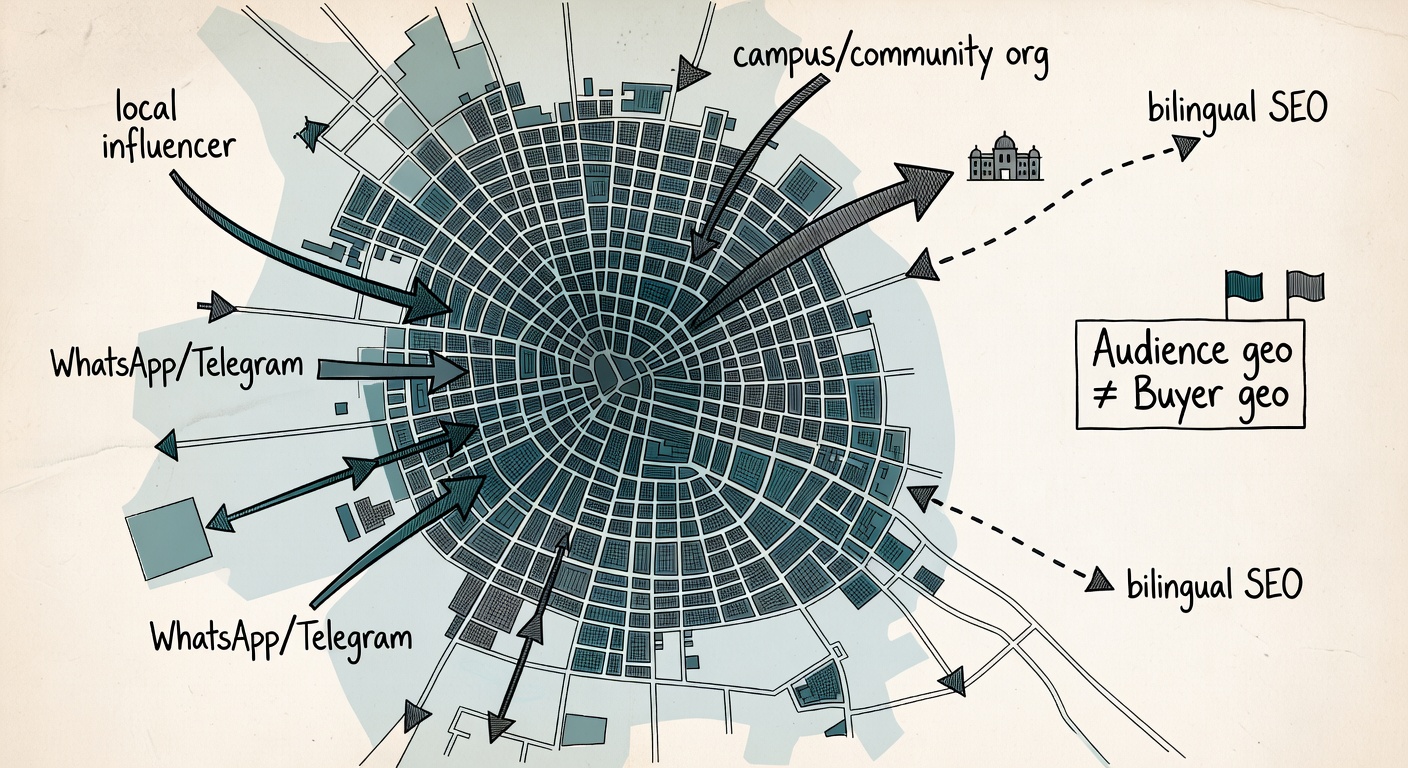
Geo-concentrated audiences (immigrant communities, local media, single-country SEO)
I’ve had pages where 85–95% of clicks come from one country or even one metro. That’s not automatically suspicious. Sometimes it’s just good targeting.
Legit reasons this happens:
- Bilingual content that ranks in one country (or one language community).
- A local influencer drop (one city, one time zone).
- WhatsApp/Telegram community sharing (tight social graph, tight geo).
- Campus/community org traffic (yes, it’s real; yes, it looks “clustered”).
Now, map that to common fraud heuristics and you see the problem. Impact calls out “traffic from unexpected locations” as a fraud signal. (impact.com) Rewardful also talks about geo mismatch checks—especially when IP geo doesn’t line up with billing/shipping. (Rewardful)
And that’s the nuance: audience geo and buyer geo aren’t always the same.
Example I’ve seen in cross-border verticals:
Traffic is 90% Canada (content ranks there), but conversions are 60% US because the product ships to the US and Canadians forward it to family. If the program expects “CA traffic → CA buyers,” you can get flagged for mismatch even when the story is normal.
So instead of hoping the model “gets it,” document the mismatch like a normal business explanation:
- “My audience is concentrated in X because Y (language/local media/community).”
- “Buyer geo differs because Z (shipping eligibility, expat purchasing, cross-border gifting, etc.).”
- A quick export of geo by clicks vs geo by conversions for the same date range (so the reviewer can see the pattern, not just read about it).
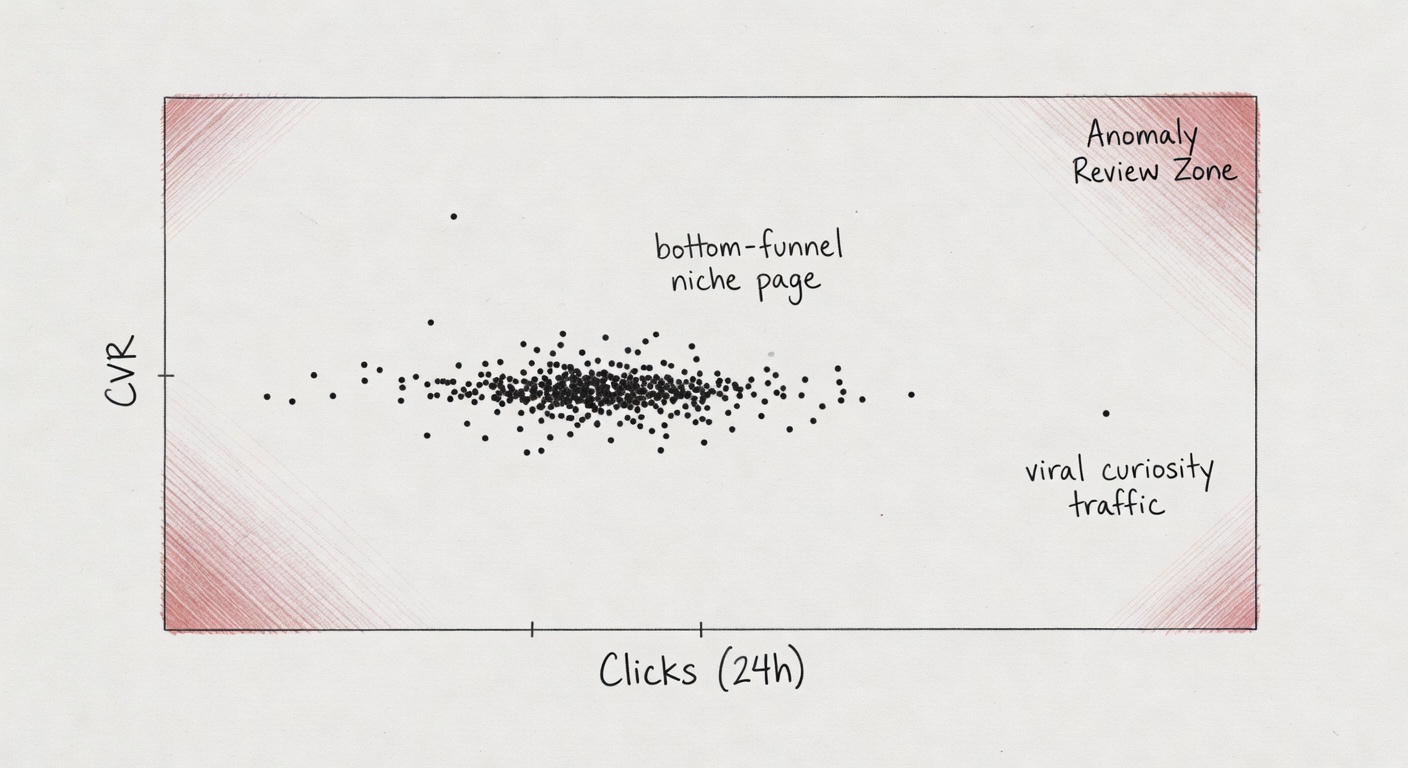
High conversion rates in narrow niches (when ‘too good’ is just good targeting)
This is the one that makes me twitchy, because it’s where good affiliates get punished for being good.
If you build bottom-funnel pages—alternatives, comparisons, “best for X condition,” “pricing,” “coupon vs no coupon” (ugh)—you can produce conversion rates that look “impossible” compared to the program average. Especially in narrow verticals where intent is high and the audience is pre-qualified.
Fraud systems may interpret “abnormally high conversion rates” as:
- Cookie stuffing
- Click injection
- Last-second attribution hijack (toolbar/extension/coupon interception)
TrafficGuard explicitly calls out “improbable funnels” and suspiciously tight click-to-conversion timing as signals models will hunt for. (TrafficGuard) Impact lists “sudden surges in conversions without corresponding engagements” as a pattern to investigate. (impact.com)
Here’s where it gets weird: legit bottom-funnel traffic often has short click-to-conversion times. If someone searches “Brand X vs Brand Y pricing,” clicks your table, and buys in 4 minutes, that’s not fraud. That’s intent.
A realistic (hypothetical) example with numbers:
A niche B2B tool page sends 600 clicks/week at 9–12% CVR because it ranks for “[tool] alternative” and the audience is already in-market. Program average CVR is 1.8%. Your traffic looks like an outlier, so it gets scored as “too good.” Meanwhile, a coupon partner with 0.9% CVR never gets touched because it’s “normal.”
The fix isn’t to sandbag performance. It’s to be able to show why the performance is high: the intent context (query/page/segment) plus your click-to-conversion distribution so “too good” becomes “high-intent and consistent.”
That tees up the next issue: if your tracking metadata looks “too clean,” you can get flagged for that, too.
SubID patterns that look “synthetic” (but are just disciplined tracking)
Advanced affiliates pass structured SubIDs because we like receipts.
But structured SubIDs can look “template-like” to systems that expect messy, inconsistent tracking. Or they see 80% of conversions tied to a small set of placements and assume manipulation.
Keywordrush lays out the reality: every network calls SubIDs something different (subid, sid, clickref, u1, etc.), but the purpose is the same—carry metadata through click → conversion. (Keywordrush)
My practice:
- Keep SubIDs consistent and human-readable.
- Maintain a mapping doc (“subid=site_page_block_creative”).
- Keep a parameter crosswalk per network (Impact subId1–subId5 vs CJ sid vs Awin clickref, etc.). (Keywordrush)
Clean SubID hygiene gives you an audit trail—so when performance gets questioned, you can explain it quickly and get reviews resolved without guesswork.
“Bridge page” misunderstandings: when your pre-sell page looks like a doorway
Pre-sell pages aren’t inherently shady. A lot of the best-performing affiliate funnels use a “middle” page on purpose: comparisons, onboarding explainers, “who this is for” pages, email landing pages that match a specific segment, or a short checklist that helps someone pick the right plan before they hit checkout.
The problem is that the same structure can also be used for garbage: thin doorway pages that exist only to push a click and capture attribution. So automated systems (and compliance teams) lean on heuristics.
Legit behavior: a pre-sell page that adds real value before the click, like:
- A comparison table with decision criteria (not just “Buy now” buttons).
- A “setup expectations” explainer (pricing, limitations, who should skip it).
- An email-specific landing page that mirrors the promise in the email.
Heuristics that trigger flags: what systems may interpret as bridge/doorway behavior:
- Thin content (low unique text, generic templates, no real decision support).
- High outbound-link ratio (page is basically a link list).
- Fast redirects or forced interstitials (especially if the user can’t meaningfully interact first).
- Low engagement (very short time on page, no scroll, pogo-sticking back to SERP).
- Repeated templates at scale (dozens of near-identical pages with swapped keywords).
- Promise mismatch between anchor/ad copy and the landing content (user expects X, page delivers Y, then pushes them out).
Google Ads is a clean cautionary example of how this gets enforced in the wild: pages that exist primarily to send users elsewhere can be treated as bridge/doorway/gateway pages, and enforcement reasons don’t always align with the underlying trigger. (Google Ads thread)
What to document: if you’re going to run pre-sell pages (and you probably are), make them defensible on paper:
- Page screenshots showing unique value and disclosure placement.
- A simple version history (what changed, when, and why).
- Notes on what’s unique about the page (original comparison criteria, original copy, original testing notes).
- Engagement exports (time on page, scroll depth, top exits) to show it’s not a dead-end click trap.
- Redirect rules and link destinations (so you can prove you’re not doing forced hops or cloaking).
Bridge-page false-positive defense packet
If a network calls your pre-sell page a “bridge,” this is the fastest way I know to turn it into a boring, reviewable asset.
- ☐ Content proof: full-page screenshots (above + below the fold), plus a note on the unique decision support (comparison criteria, original copy, original testing notes).
- ☐ Disclosure proof: screenshot showing disclosure placement in context (not cropped to the footer).
- ☐ Technical proof: redirect rules (if any), canonical handling, and how you handle UTMs/parameters (so it’s clear you’re not forcing hops or doing sneaky rewrites).
- ☐ Engagement proof: time on page, scroll depth, and top exits for the flagged window (a quick export is enough).
- ☐ Change-log proof: what changed, when, and why—especially if the page was updated right before the spike.
- ☐ Destination proof: list of outbound destinations from the page (merchant domains + any intermediate tracking domains) with timestamps.
Once your pre-sell pages are documented like this, the rest of the article gets easier—because you’re building the same thing everywhere: an audit trail that makes “anomaly” explainable.
2) Build your documentation trail before you need it (so ‘anomaly’ becomes explainable)
Fraud teams aren’t trying to understand your business model. They’re trying to reduce risk.
And at scale, they have to rely on automation. Impact’s guidance basically admits the operational reality: manual monitoring works at 10 partners and collapses at 50+, so platforms push automated scoring and alerts. (impact.com) Affiverse makes the same point from the compliance side: Rightlander scans “around 1.2 million pages and posts every day.” Humans can’t keep up. (Affiverse)
So your job, as a legitimate affiliate, is to make your traffic auditable.
Keep a ‘change log’ for every spike: what changed, when, and why
I keep a change log like a lab notebook. It’s boring. It works.
For every meaningful spike (or dip), I log:
- Content publish/update time
- Email send time + segment name
- Influencer post time + link format (bio, story, pinned comment)
- Any paid boost (even small)
- Link swaps, redirect changes, tracking template changes
- Offer/creative updates (new coupon, new landing page, pricing change)
Affiverse’s “legacy content” point matters here: old pages can become current risk because offers expire and policies change. (Affiverse)
If this feels strict, good—it means you’re building something that can survive volatility.
Capture placement proof: URLs, screenshots, and referral context (not just ‘trust me’)
When a network asks “where is this traffic coming from,” “my site” is not an answer. It’s a shrug.
What I store:
- Exact URLs where links live (not just domain)
- Screenshots of the page including disclosure placement
- Referrer context: post URL, thread URL, newsletter issue ID, or creator handle
- If it’s social: capture the post text + timestamp (stuff gets edited/deleted)
And yes, I bulk-audit my placement URLs periodically for status codes, redirect chains, and “oops this page is now 404” issues. I’ve used LinksTest for that kind of bulk URL auditing as part of the documentation process—mostly because I want a clean list I can hand to someone without arguing about which pages were live.
Small note: this also protects you from accidental compliance problems. A broken redirect chain can look like cloaking when it’s really just sloppy ops.
The win isn’t a spike. The win is a system you can trust next month.
Instrument SubIDs like you expect to be questioned later
If you’re already doing SubIDs, tighten them up. If you’re not, start.
What I recommend (simple, stable, explainable):
- sub1: site/property
- sub2: page or content ID
- sub3: placement block (table/button/sidebar)
- sub4: traffic source tag (seo/email/social/referral)
- sub5: creative/version (A/B variant, date code)
Then keep a mapping sheet and a network parameter crosswalk. Keywordrush’s list of network aliases is a good reminder that “SubID” isn’t universal language. (Keywordrush)
Store the mapping somewhere you can export fast. Future-you will thank you.
Pre-empt the classic fraud heuristics with your own QA reports
Once a month, I generate a lightweight “normal ranges” packet:
- Top geos + % share
- Device mix
- Click-to-conversion distribution (median + tails)
- Top referring pages
- Any refund/chargeback signal I can access (rare, but gold when you have it)
Impact’s red flags are basically the checklist: repeated IP/device, unexpected locations, low session duration, odd spikes. (impact.com) Rewardful’s guide is similar—mismatch patterns, suspicious behavior, etc. (Rewardful)
You don’t need perfection. You need a baseline you can show—so when the model says “anomaly,” you can answer with “expected, documented, and repeatable.”
3) When a network flags or suspends you: what to ask, what to send, and how to get unstuck
This is the part nobody wants to practice.
But you should.
Your goal is not to “win an argument.” It’s to get the case out of automated enforcement and into a human review queue with enough context that the reviewer can close it.
First response: confirm the clock, the scope, and what’s frozen
First email back, I ask three things:
- What is the action type? Temporary hold, compliance review, or termination?
- What is the scope? Which offers/advertisers, which tracking IDs, which date range?
- What is frozen? Clicks only? Conversions? Commissions? For how long?
Platforms sometimes spell this out clearly. TikTok Shop, for example, states creators can appeal violations within 30 days, and if approved, the enforcement action is removed. (TikTok Shop policy) It also states commissions can be withheld for up to 90 days, and late appeals may mean frozen commissions are forfeited. (TikTok Shop policy)
That’s not affiliate-network universal. But it’s a good reminder: there’s a clock even when nobody highlights it in bold.
Don’t skip this step.
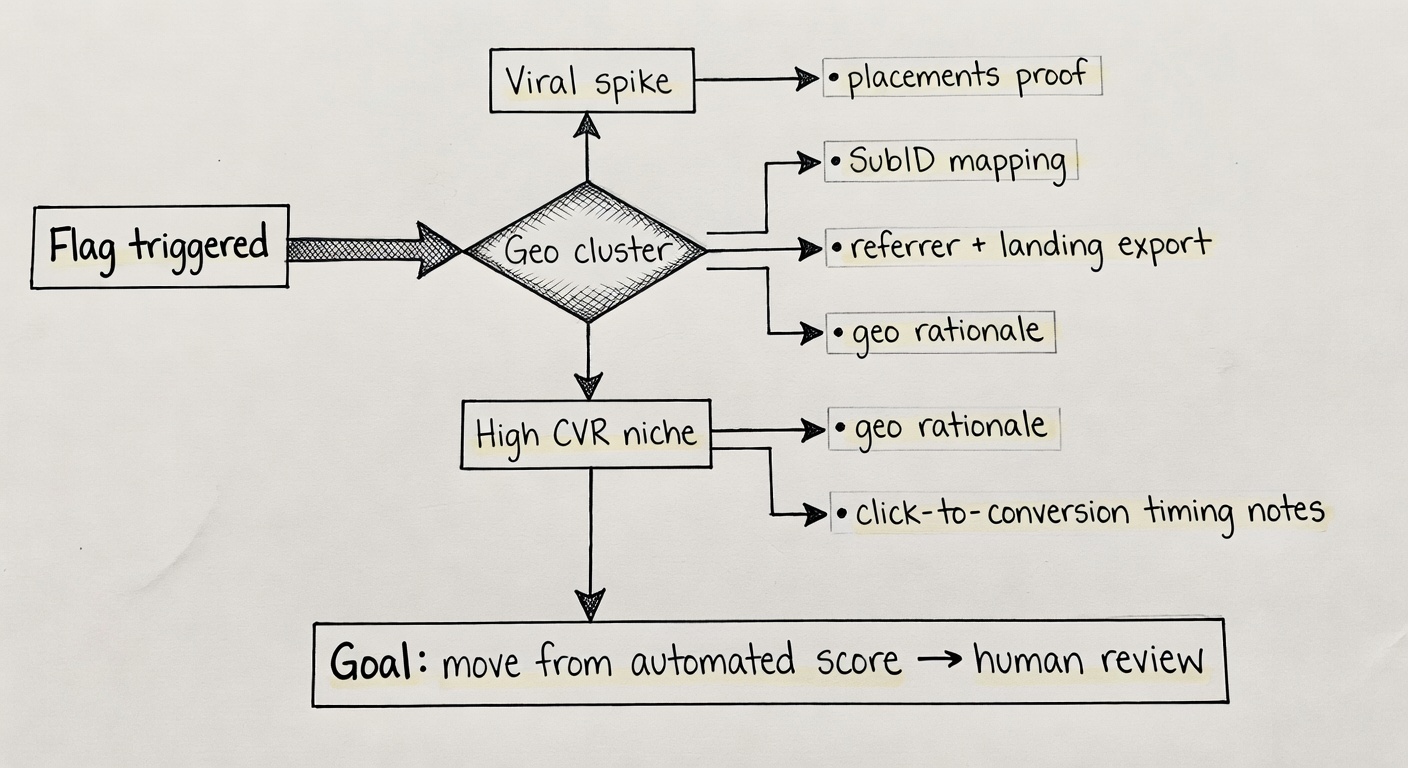
Your ‘dispute packet’: the minimum evidence that changes the conversation
I keep a standard bundle ready. When something hits, I can ship it in an hour.
My minimum dispute packet:
- Top placements list (URLs) + screenshots (include disclosure)
- SubID mapping + a few sample rows from reports (click → conversion)
- Spike explanation: timestamps + referrer URLs + “what changed” from the change log
- Geo rationale: why the audience is concentrated + any known buyer-geo nuance
- Traffic acquisition statement: no incentivized, no bots, no forced clicks, no toolbars/extensions (keep it factual)
- Third-party analytics exports: GA4 landing pages, referrers, device/geo breakdown, server log snippets if available
This aligns directly with what networks say they look for: spikes, unexpected geos, repeated patterns, low session duration, mismatches. (impact.com; Rewardful)
One more wrinkle: keep it tight. Reviewers are triaging. A 40-page PDF of vibes won’t help you.
I’d rather you ship one clean packet than ten messy emails you can’t explain.
What to request from the network (even if they won’t tell you everything)
You won’t always get the exact model trigger. Fine.
But you can usually get enough to respond if you ask precisely:
- Which transaction IDs (or order IDs) are flagged?
- What time window is under review?
- Which rule category is implicated: IVT/bot, policy/compliance, attribution manipulation?
- Is the issue click-side (traffic quality) or conversion-side (chargebacks, stolen cards, lead quality)?
And I keep expectations realistic. Google Ads is a good reminder that enforcement labels can be misleading; “reasons don’t always align with the real reason.” (Google Ads thread)
So don’t get stuck debating the label. Get the scope, then rebut with data.
In practice, reviewers are scanning for a clear, verifiable explanation—so package your evidence in a way that’s fast to validate and hard to misread.
If it’s a policy/compliance flag, don’t argue—remediate and show the diff
If the issue is disclosure placement, expired offers, unapproved placements, or creative claims, I don’t write a philosophy essay.
I fix it and document it:
- Before/after screenshots
- URLs updated/removed
- Dates/times of changes
- A short remediation log
Affiverse’s “legacy content” warning is real: old posts can violate current rules without you noticing. (Affiverse) TikTok Shop’s policy language also makes it clear that repeated violations can escalate quickly. (TikTok Shop policy)
The fastest reinstatements I’ve seen come from a clean remediation log, not a debate.
When you communicate with the network, keep it operational: scope, evidence, remediation, and the exact transactions you’re asking them to reinstate.
A quick reality check: you’re not trying to ‘prove innocence’—you’re trying to be auditable
Fraud systems optimize for risk reduction, not affiliate feelings.
Annoying, but true.
So I don’t aim to “prove” I’m legitimate in some abstract sense. I aim to make my traffic easy to verify. Boring to review. Consistent with a documented story.
ACAMS’ warning about algorithm dependence without verification maps cleanly here: false positives create real damage when nobody slows down to validate the context. (ACAMS) TrafficGuard’s rules-to-ML framing also implies the same operational truth: anomaly detection needs context, and context often lives outside the model. (TrafficGuard)
One concrete next step for this week: build (or tighten) your change log and SubID schema, then run a placement audit so you can produce receipts on demand.
If you’ve seen a different false-positive pattern lately, what was your partner mix and traffic source?
Dispute packet template (what to send when you get flagged)
If you want the “send this, not a rant” version, here it is. The goal is to move your case from automated scoring to human review with enough context to close it.
- ☐ Spike narrative: what happened, when it started, when it peaked, when it normalized (include timestamps) + the referrer URLs (post/thread/newsletter issue/creator handle).
- ☐ Placement proof: list of top URLs driving clicks + screenshots showing the link placement and disclosure in context.
- ☐ SubID mapping excerpt: your SubID schema + a small sample of click → conversion rows (enough to show it’s consistent and explainable). (Keywordrush)
- ☐ Geo rationale: audience geo vs buyer geo explanation + an export showing geo by clicks and geo by conversions for the flagged window. (Rewardful)
- ☐ Click-to-conversion distribution: median time-to-convert plus a quick look at the tails (so “fast conversions” reads as “high intent,” not “injection”). (TrafficGuard)
- ☐ Compliance confirmation: disclosures present, no forced redirects, no cloaking, no incentivized traffic, no toolbars/extensions—keep it factual and specific to the flagged placements. (impact.com)
Send that as one tight email (or one attachment bundle), then ask them to confirm the scope: which transaction IDs, which date range, and whether the concern is click-quality or conversion-quality.
Key Takeaways
- False positives aren’t random. Viral spikes, geo clusters, and niche high-intent pages map directly to common fraud heuristics like click velocity, “unexpected locations,” and “abnormally high conversion rates.” (impact.com)
- Make “weird” explainable before it happens. A change log + placement proof + SubID mapping turns an anomaly score into a story a reviewer can verify.
- Bottom-funnel performance can look like manipulation. Short click-to-conversion times and high CVR are normal for alternatives/pricing/comparison intent—if you can show the distribution and the context. (TrafficGuard)
- Pre-sell pages are fine—thin doorway pages aren’t. Document content uniqueness, redirects, engagement, and version history so “bridge page” doesn’t become a vague reason to freeze payouts. (Google Ads thread)
- When you get flagged, ship a dispute packet—not vibes. Your fastest path is evidence that moves you from automated scoring to human review: spike narrative, placements, SubIDs, geo rationale, and click-to-conversion distribution. (Rewardful)
Sources
- ACAMS — Artificial Intelligence: The Implications of False Positives and Negatives
- impact.com — Affiliate Fraud: How to Detect and Prevent it From Happening
- TrafficGuard — Affiliate Fraud Detection: From Rule-Based Checks to Machine Learning
- Rewardful — Guide to Detecting and Preventing Affiliate Fraud
- Keywordrush — Dynamic SubID Tracking for Smarter Affiliate Marketing
- TikTok Shop — Creator Enforcement Policy
- Google Ads Help Community thread — suspension / circumventing system policy
- Affiverse — The Hidden Affiliate Risk That Could Sink Your Brand