
Blockchain Affiliate Attribution Models: Transparent Tracking Without the Hype
Blockchain-based transparent affiliate attribution models (without lying to yourself about what’s “provable”)
I keep seeing affiliate programs built like a junk drawer—everything tossed in, nothing labeled, and somehow we’re surprised when it jams.
Now swap “junk drawer” for “attribution.” Same vibe. Everyone wants transparent commission distribution, fewer reversals, and less black-box reporting. And yes, blockchain-based transparent affiliate attribution models can help—mostly by giving you a cleaner audit trail and fewer “he said / she said” payout fights.
Here’s the thesis: blockchain can make events harder to tamper with and easier to reconcile, but it can’t magically prove intent, incrementality, or identity across devices. Prove the event, not the intent. That’s the whole point.
If you’re evaluating decentralized affiliate tracking systems, this is the operator’s guide I wish more people wrote.
Start with the boring definition: what “affiliate attribution” is actually doing (who gets paid, how much, when)
Affiliate attribution isn’t just measurement. It’s a payout policy with analytics attached.
Trackier defines affiliate attribution as “the process by which a brand, network, or affiliate platform identifies, tracks, and assigns credits to the specific affiliates and marketing touchpoints that contribute to a particular outcome…” like a sale or lead (Trackier). And they say the quiet part out loud: in simpler terms, attribution defines who gets paid, how much, and when (Trackier).
So if your attribution logic is messy, your partner relationships will be messy. Predictably.
If you only remember one thing from this section, make it this: attribution policy = payout policy.
Exactly.
Single-touch vs multi-touch: the model choice changes partner behavior (and your disputes)
Single-touch models are the classics: first-click or last-click. Easy to explain. Easy to implement. Easy to accidentally incentivize the wrong behavior.
Multi-touch attribution, per Nielsen, “takes all of the touchpoints on the consumer journey into consideration and assigns fractional credit to each” (Nielsen). Trackier lists common models you’ll recognize: linear, time-decay, position-based, and data-driven (Trackier).
Here’s where last-click gravity shows up. Coupon and deal partners tend to “close” (or intercept) at checkout, which can be valuable—but if they get all the credit, TOFU content partners get trained to stop doing TOFU work. Then brands complain “content doesn’t scale.” I hate how often this gets glossed over.
Comparison: A compact table comparing single-touch (first/last click) vs multi-touch (linear/time-decay/position-based/data-driven) across: how credit is assigned, typical affiliate winners/losers (content vs coupon/deal), implementation complexity, dispute risk, and best-fit use cases. Include a row for “what partners can audit/reproduce.”
| Dimension | Single-touch (First-click / Last-click) | Multi-touch (Linear / Time-decay / Position-based / Data-driven) |
|---|---|---|
| How credit is assigned |
100% of credit to a single touchpoint:
|
Credit is split across multiple touches:
|
| Typical affiliate winners / losers Content vs coupon/deal |
|
More balanced by design (depending on weights):
|
| Implementation complexity |
Low:
|
Medium to high:
|
| Dispute risk |
Predictable but often contentious:
|
Lower “winner-takes-all” conflict, but more debate about the math:
|
| Best-fit use cases |
|
|
| What partners can audit / reproduce |
High reproducibility:
|
Varies by model:
|
So before you change commissions, check the conversion path—otherwise you’re paying to mask a site problem.
Question to stress test your model: What behavior are you paying for—discovery, persuasion, or checkout interception?
Rules-based vs algorithmic attribution: transparency tradeoff you can’t hand-wave away
Nielsen draws a clean line: rules-based methods are subjective because marketers define the rules; algorithmic approaches use statistical modeling and machine learning techniques (Nielsen).
Rules-based is explainable. Algorithmic can be more accurate (in theory) but harder to justify to partners. And partners don’t trust what they can’t reproduce.
So publish a plain-English policy. Put the math in an appendix. Give people an audit trail. Or accept the disputes as a cost of doing business.
Alright, now we can talk tactics without lying to ourselves.
What blockchain changes (and what it doesn’t): audit trails, timestamps, and shared ledgers
Blockchain is best understood as a record layer. A shared ledger.
Verifi describes it this way: “Blockchain uses a shared, secure ledger to track and approve each component… within a transaction,” with blocks connected and timestamped to prove who did what and when (Verifi). That “timestamp + shared record” idea is the part affiliate teams should care about.
ZigPoll’s piece frames blockchain credentialing as creating “tamper-proof, cryptographically verifiable records” and replacing vulnerable centralized databases with “immutable proofs” that are auditable (ZigPoll).
But the annoying part people skip: an immutable record doesn’t mean a true record. It means a permanent one.
Immutable records: great for disputes, useless if you log the wrong thing
Garbage in. Immutable garbage out.
If you anchor the wrong event (or the wrong identity mapping, or the wrong dedupe rule), you’ve just made your mistake harder to unwind. This is why I keep a change log like a lab notebook—otherwise you’re just telling yourself stories.
Operationally, you want canonical events with a versioned schema:
- Click (or view, if you’re doing view-through—be careful)
- Lead created (with eligibility checks)
- Conversion (sale / subscription / on-chain tx)
- Refund / chargeback / reversal
- Payout executed (or withheld)
And yes, you need to version them. When you change attribution windows or dedupe rules, that’s a schema change. Treat it like one.
Run the boring checks first. They catch the expensive problems.
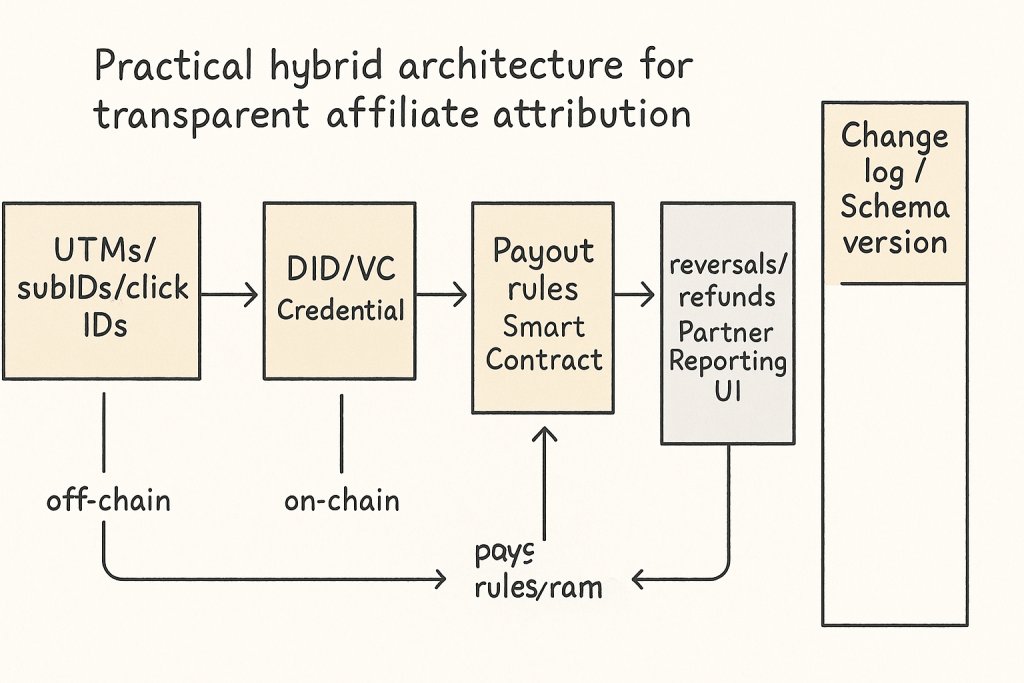
A practical architecture for transparent attribution: off-chain UX, on-chain proofs, and verifiable credentials
Most teams don’t need “everything on-chain.” They need verifiable receipts.
ZigPoll lays out a pragmatic pattern: decentralized identity (DID) + verifiable credentials (VCs), smart contracts for attribution workflows, optional zero-knowledge proofs (ZKPs) for privacy, and cross-channel credential aggregation (ZigPoll).
I’m going to flatten this a bit into a reference model:
Features & Specs
| Feature | Details |
|---|---|
| Off-chain tracking |
Purpose: Capture user journey events (click → session → conversion) with low latency and flexible logic; produce an auditable event log that can later be anchored/proved.
Data stored: Event IDs, timestamps, campaign/partner IDs, referrer/UTM, device/browser signals, order/lead metadata, dedupe keys, fraud signals; often stored in a warehouse + append-only log.
What’s provable: That a specific event record existed in your system at/after a time (if you hash/sign logs); that your stated attribution rules were applied to the recorded inputs (if you publish code + inputs). Not provable: user intent, incrementality, cross-device identity without additional trust assumptions.
Privacy considerations: Highest risk layer—contains identifiers and behavioral data; minimize PII, use pseudonymous IDs, consent management, retention limits, and access controls; avoid leaking raw clickstream to partners.
Common failure modes: Cookie loss/ITP, ad blockers, cross-device gaps, clock skew, duplicate events, attribution “last-mile” hijacking, bot traffic, inconsistent schemas across services, unverifiable “black box” rule changes.
|
| VC issuance (Verifiable Credentials) |
Purpose: Turn key off-chain facts (e.g., “Partner X referred Order Y under policy Z”) into portable, cryptographically signed claims that can be verified by third parties.
Data stored: Credential payload (claims), issuer DID, subject identifier (often a DID or pseudonymous ID), issuance time, schema ID/version, status/revocation reference; optionally selective-disclosure/ZK proofs.
What’s provable: Authenticity (issuer signature), integrity (unchanged claims), and (optionally) non-revocation at verification time. Not provable: that the underlying off-chain event is “true” beyond the issuer’s trust; VC proves “issuer attests,” not “objective reality.”
Privacy considerations: Avoid embedding PII/order details in cleartext; use pairwise DIDs, minimal claims, selective disclosure, and unlinkability strategies; consider correlation risk if the same subject ID appears across partners.
Common failure modes: Key compromise/rotation mishandling, ambiguous schemas, unverifiable issuer reputation, revocation/status outages, over-sharing claims (privacy breach), credential replay without binding to context, inconsistent subject identifiers.
|
| On-chain anchoring |
Purpose: Provide a shared, tamper-resistant timestamped reference for off-chain logs/credentials (e.g., Merkle root of events or issued VCs) to reduce “he said / she said” disputes.
Data stored: Hashes/Merkle roots, batch IDs, policy/schema version pointers, issuer identifiers, optional commitments; no raw clickstream.
What’s provable: Existence and integrity of a committed dataset at/after a block time; inclusion proofs (event/VC ∈ anchored batch). Not provable: that the dataset is complete (you can omit events), that timestamps reflect real-world time precisely, or that inputs weren’t manipulated before anchoring.
Privacy considerations: Hashes can still leak via dictionary attacks if inputs are guessable (e.g., order IDs); use salted commitments, batching, and avoid anchoring low-entropy identifiers.
Common failure modes: Anchoring delays (weakens dispute resolution), chain reorg/finality assumptions, gas cost spikes, incorrect Merkle construction, anchoring the wrong dataset/version, reliance on a single chain without contingency.
|
| Smart contract payout |
Purpose: Automate commission calculation and settlement (or escrow + release) based on verifiable inputs; make payout rules inspectable and execution deterministic.
Data stored: Commission schedules, partner addresses, escrow balances, payout states, references to anchored batches/claims, dispute windows, admin roles; sometimes minimal per-conversion commitments.
What’s provable: That payouts followed the on-chain rules given the on-chain inputs; that funds moved to specified addresses; that a claim was accepted/rejected per contract logic. Not provable: correctness of off-chain attribution inputs unless verified via proofs/oracles you trust.
Privacy considerations: On-chain transparency exposes partner earnings and timing; consider batching, mixers/privacy L2s (where appropriate), or keeping sensitive breakdowns off-chain while paying aggregated amounts.
Common failure modes: Oracle/attestation trust bottlenecks, contract bugs, admin key abuse, upgrade risks, rounding/edge-case errors, griefing via disputes, address misbinding (wrong partner wallet), regulatory/chargeback mismatch with irreversible settlement.
|
| Partner UI / reporting |
Purpose: Make attribution and payouts legible to partners: show paths, credited touchpoints, policy versions, and proof artifacts (VCs, inclusion proofs, tx links).
Data stored: Aggregated metrics, drill-down views, downloadable reports, proof bundles (VC + Merkle proof + anchor tx), dispute tickets, API tokens.
What’s provable: Partners can independently verify signatures, inclusion proofs, and on-chain payouts; they can reproduce totals from shared datasets if provided. Not provable: UI claims that aren’t backed by downloadable/verifiable artifacts.
Privacy considerations: Prevent partner-to-partner data leakage; enforce row-level security; redact user-level data; be careful with “path” views that could expose personal behavior.
Common failure modes: “Proof theater” (links without verifiable data), mismatched totals vs on-chain, confusing policy explanations, API drift, caching stale states, inability to export evidence for disputes/audits.
|
| Change log / schema versioning |
Purpose: Make attribution policy and data model evolution explicit so historical payouts remain explainable; bind events/VCs/anchors to the exact rules and schemas used.
Data stored: Versioned schemas, policy documents, contract versions, migration notes, effective dates, hash pointers to canonical docs (optionally anchored on-chain), deprecation timelines.
What’s provable: That a given payout/event referenced a specific policy/schema version; that the published document hasn’t changed (if hashed/anchored). Not provable: that stakeholders understood/consented—only that the version existed and was referenced.
Privacy considerations: Low direct privacy risk, but avoid embedding sensitive operational details (fraud heuristics) that could be exploited; publish summaries with controlled internal detail.
Common failure modes: Silent rule changes, backward-incompatible schema updates, missing effective-date boundaries, inability to replay historical attribution, “version drift” between UI, issuer, and contract, broken links to canonical policy docs.
|
- Off-chain tracking captures touchpoints (UTMs, subIDs, click IDs, email IDs, influencer codes—whatever you use).
- At lead capture or key milestones, issue a verifiable credential (VC) representing a claim like “Lead Verified” or “Purchase Completed” (ZigPoll).
- Anchor a proof on-chain (hashes, timestamps, credential references).
- Smart contract enforces payout rules once the credential is validated (ZigPoll).
- Keep your UI and partner reporting friendly. Nobody wants to read raw transactions all day.
Anyway—back to the funnel.
Decentralized identity (DID) for lead verification: prove eligibility without exposing PII
ZigPoll’s argument is that DIDs are user-controlled identities anchored on-chain, enabling VCs without relying on centralized authorities (ZigPoll).
This can support privacy-preserving designs. It’s not an automatic “we’re compliant now” button. (If someone tells you it is, close the tab.)
But it does give you a way to prove “this lead met criteria X” without dumping PII into every partner’s hands.
Zero-knowledge proofs (ZKPs): when you need validation without data leakage
ZigPoll describes ZKPs as a way to prove a statement is true without revealing underlying data, and suggests integrating ZKP verification into smart contracts for privacy-preserving validation (ZigPoll).
My read is: ZKPs are great when you must validate something sensitive (eligibility, purchase occurred, user is in region) without exposing the details. But they add complexity fast.
Pilot it on one event type first. One.
✅ Pros
- Validate eligibility (e.g., “new customer,” geo, minimum basket) without exposing PII
- Selective disclosure: prove only the required attributes, not the underlying user data
- Stronger partner trust for sensitive claims (less “trust me” reporting, fewer payout disputes)
Use when: you need to prove policy compliance or eligibility while keeping user data private.
❌ Cons
- Higher engineering complexity (circuits, key management, integration)
- Verification costs and added latency (especially at scale)
- Harder debugging and incident response (opaque proofs vs readable logs)
- Limited partner comprehension (education burden, adoption friction)
Avoid when: a simpler audit trail + clear policy is sufficient, or partners need fast, easily explainable reconciliation.
Smart contracts for payout execution: the cleanest way to reduce ‘we’ll pay you next month’ drama
If you’ve ever stared at a reversal report at midnight, you’ll get why instant, deterministic payout logic is appealing.
WP Smart Contracts’ docs explicitly say: “Commissions are automatically distributed by the factory smart contracts at the moment of smart contract deployment on the blockchain” (WP Smart Contracts docs). That’s not theory. That’s a shipped mechanism.
Here’s the catch: affiliate payouts aren’t always final at the moment of conversion.
Refunds happen. Chargebacks happen. Fraud happens. So if you automate payout, you also need to encode (or operationalize) clawbacks, hold periods, or escrow logic. Otherwise you’re just moving the argument from “why was I reversed?” to “why are you taking money back?”
No tracking. No trust.
Attribution models you can encode on-chain (and the parts you probably shouldn’t)
Trackier’s list of common attribution models maps pretty cleanly to smart contract logic for rules-based setups (Trackier). Nielsen’s framework helps you separate rules-based from algorithmic approaches (Nielsen).
So before you go full Web3 attribution maximalist, pick what you want to encode.
Single-touch on-chain: simple, auditable, and still biased
Last-click and first-click are the MVPs. They’re deterministic.
You can encode:
- attribution window (e.g., 7 days)
- eligible touchpoint types
- dedupe rules (one conversion → one payout)
- payout rate / tiers
And you can anchor the click + conversion events so partners can audit timestamps and eligibility.
But the bias remains. Nielsen calls out that rules-based approaches can skew measurement by arbitrarily applying rules (Nielsen).
So yes—auditable bias is still bias.
Rules-based multi-touch on-chain: linear, time-decay, position-based
Trackier outlines linear, time-decay, and position-based models (Trackier). These are feasible on-chain if you store or anchor multiple touchpoints per conversion.
Operational requirements you can’t skip:
- a canonical touchpoint format (channel, partner ID, timestamp, subID)
- a weighting function (the math)
- a cap / floor policy (so micro-touch spam doesn’t farm pennies)
Publish the weighting math. Seriously. If partners can’t reproduce the math, they’ll assume you’re shaving.
If this feels strict, good—it means you’re building something that can survive volatility.
Algorithmic models: keep the model off-chain, put the receipts on-chain
Nielsen describes algorithmic methodologies as using statistical modeling / ML techniques (Nielsen).
Most teams should not run ML models on-chain. Cost, complexity, and explainability get ugly.
The pattern I like is:
Comparison: Table contrasting three approaches: (1) rules-based on-chain, (2) algorithmic off-chain + on-chain receipts (hashes/model version), (3) fully on-chain modeling (discouraged). Compare on: explainability, cost, auditability, partner trust, iteration speed, and data access/privacy constraints.
| Dimension | 1) Rules-based on-chain | 2) Algorithmic off-chain + on-chain receipts (hashes/model version) | 3) Fully on-chain modeling (discouraged) |
|---|---|---|---|
| Explainability | High. Deterministic rules (e.g., last-click, time-decay) are easy to describe and reproduce from on-chain events. | Medium. You can explain the policy and publish model docs, but most partners can’t independently re-run the model without the same data + pipeline. | Low–Medium. Logic is visible, but complex models become opaque in practice (and hard to interpret from smart contract code). |
| Cost | Low–Medium. On-chain computation is limited but manageable for simple rules; gas costs scale with event volume. | Medium. Compute happens off-chain (cheap), but you still pay to write receipts/commitments on-chain; operational cost shifts to infra + monitoring. | High. Heavy computation and storage on-chain is expensive; costs grow quickly with model complexity and data volume. |
| Auditability | High. Inputs and rule execution are verifiable on-chain; disputes reduce to “did the event happen?” and “what did the rule say?” | High for integrity, Medium for reproducibility. Receipts (hashes, model version, parameters) prove what was used, but not necessarily that everyone can recompute without access to the same data. | High in theory. Everything is on-chain, but practical auditing is hindered by complexity, upgrade patterns, and data constraints. |
| Partner trust | High. Partners can understand and verify outcomes; fewer “black box” accusations. | Medium–High. Trust improves if you publish model cards, change logs, and on-chain receipts; still requires confidence in off-chain data handling and governance. | Medium. “It’s on-chain” sounds trustworthy, but partners may distrust complexity and fear hidden assumptions embedded in code. |
| Iteration speed | Medium. Rule changes require contract upgrades/governance and careful backward compatibility. | High. Models can be retrained and redeployed off-chain quickly; on-chain receipts provide a stable reference for “which version paid this.” | Low. Upgrading complex on-chain logic is slow, risky, and governance-heavy; experimentation is constrained by gas and immutability. |
| Data access / privacy constraints | Strict. You should avoid putting sensitive user-level data on-chain; rules must work with minimal, privacy-safe event data. | Flexible. Sensitive features can stay off-chain; on-chain stores only commitments (hashes), model IDs, and payout outputs—better fit for privacy and data minimization. | Severe. On-chain data is public by default; privacy-preserving approaches (e.g., ZK) add major complexity and cost, and still limit feature richness. |
- Compute weights off-chain (your model, your infra).
- Commit the inputs hash + model version + outputs hash on-chain.
- Store the full dataset off-chain (with access controls).
- Give partners an audit path: “Here’s the model version, here’s the touchpoint set used, here’s the resulting split.”
Verifi’s framing of blockchain as a shared ledger with timestamps is useful here—your chain becomes the “receipt layer,” not the brain (Verifi).
Try it on one offer, one partner type, one traffic source. Then scale what holds up.

Cross-channel and cross-platform attribution: where blockchain helps, and where it still hurts
This is the messy middle.
ZigPoll suggests “cross-channel credential aggregation” to unify attribution across email, social, search, etc., using verifiable credentials (ZigPoll). Trackier also calls out how multi-channel journeys complicate attribution and create tracking gaps (Trackier).
Blockchain helps when you need a shared record across parties. It doesn’t solve identity resolution by itself.
One more wrinkle: cross-device is still cross-device. If you can’t connect the user journey, you can’t allocate credit perfectly. That’s true—well, true in most verticals.
Credential aggregation: unify touchpoints without rebuilding your whole stack
The rollout I’d actually ship:
- Start with content + email (two channels you can control and instrument well).
- Issue a VC for “touchpoint occurred” at each meaningful event.
- Anchor proofs on-chain.
- Validate at conversion time, then pay.
Then expand to influencers, paid, and whatever else you’re brave enough to integrate.
And keep a change log. Always.
The win isn’t a spike. The win is a system you can trust next month.
Fraud, reversals, and ‘creative’ partners: using on-chain data as a fraud tripwire
A lot of “blockchain prevents fraud” content is… aspirational.
Verifi is more honest: blockchain “while not a panacea, could be a marked improvement,” and even then breaches can happen (they cite the Bitfinex hack as an example of key compromise) (Verifi).
So treat on-chain data as traceability, not immunity.
On-chain analytics for anomaly detection: what to flag (and what not to overreact to)
ZigPoll recommends using on-chain analytics tools to monitor transactions and flag suspicious patterns like repeated credential issuance (ZigPoll).
What I’d flag:
- unusually high VC issuance per DID in short windows
- repeated conversions with identical touchpoint sequences
- sudden partner mix shifts (new partner claiming large share overnight)
- high conversion rate with low engagement signals (depends on your funnel)
What I wouldn’t overreact to:
- legitimate spikes from a real placement (verify with referrer + creative + timestamp clustering)
- seasonal promos (your model should know your promo calendar, but it usually doesn’t)
Set an escalation playbook. Human review still matters. Annoying, but true.
Pay attention to the incentive here.
Tokenized incentives and on-chain commissions: when ‘transparent’ economics helps (and when it’s just noise)
Token rewards can align incentives. They can also add volatility and regulatory headaches. Both can be true.
On-chain recorded transactions as commission basis (CoinFactory-style): simple transparency win
CoinFactory describes an affiliate program paying 30% to 50% commission and claims “every transaction is recorded on-chain, making your income fully transparent and verifiable” (CoinFactory).
That’s a clean model when the conversion event is an on-chain transaction.
Small note: the referral mapping (who referred whom) can still be off-chain depending on implementation. So if you’re copying this pattern, be explicit about what’s provable on-chain vs what’s asserted by your app.
Profit-sharing + token rewards (Qzino-style): aligns partners to platform performance, adds new risks
The Qzino affiliate program write-up (reposted by MEXC) describes daily profit sharing, tokenized rewards, and “up to 30% lifetime revenue share,” plus a mechanism allocating “up to 50% of platform revenue” to token holders (MEXC / Qzino article).
This aligns affiliates with platform performance. It also exposes them to token price risk and jurisdictional constraints. And disclosure obligations don’t disappear just because payouts are in tokens.
If you’re a publisher: would you promote this offer if you weren’t getting paid?
Real-world patterns: what decentralized affiliate networks are actually shipping
Most posts stay theoretical. I’d rather point to things that exist.
droplinked: on-chain attribution + automated commissions for decentralized product listings
droplinked’s docs say their affiliate page connects producers and publishers, “automating payment processes and earned commissions,” and that the automated affiliate network “provides on-chain attribution” (droplinked docs).
What to learn from this pattern:
- partner onboarding matters more than the chain
- attribution event definition is the real product
- automated commissions reduce payout friction (until refunds enter the chat)
Okay—now let’s look at what breaks when you scale it.
WP Smart Contracts: factory smart contracts paying affiliates at the moment of deployment
WP Smart Contracts is explicit about instant distribution: “Commissions are automatically distributed… at the moment of smart contract deployment” (WP Smart Contracts docs). Their affiliate page also advertises a 40% commission rate and lists platform stats like “$35,000,000+ Smart Contracts Value Locked” and “2,000+ Mainnet Deployments” (WP Smart Contracts).
This is a great example of event-driven payout where the “conversion” is a blockchain deployment.
If your conversion is a physical product shipment, you’ll need different settlement logic. Don’t copy/paste blindly.
Affiso (Cardano Catalyst proposal): trustless campaigns as a concept (not approved, but instructive)
Affiso is listed on Project Catalyst with Status: Not approved (Project Catalyst). Still, it’s useful as a conceptual reference: smart contracts for “trustless, transparent, and automated marketing campaigns,” with an emphasis on transparency via open smart contract code (while keeping some proprietary logic private) (Project Catalyst).
Takeaway: even in decentralized designs, teams often keep parts of the system off-chain. That’s normal. Just document it.
You don’t need more tactics; you need fewer unknowns.
Implementation roadmap: MVP that’s auditable before it’s ‘advanced’
ZigPoll basically begs people to implement in stages (DID → smart contracts → ZKP → aggregation → incentives → fraud analytics) (ZigPoll). Trackier emphasizes that model choice depends on your customer journey, goals, and data readiness (Trackier).
So here’s the staged plan I’d run:
- Define canonical events + attribution window (and write it down).
- Issue VCs at lead capture (or at the first verifiable milestone).
- Anchor proofs on-chain (hash + timestamp + schema version).
- Smart contract payout for one conversion type (one).
- Add hold periods / clawback logic if refunds exist.
- Expand channels via credential aggregation.
- Add ZKPs only where privacy demands it.
- Add fraud tripwires using on-chain analytics patterns.
Timeline
Define the minimal event schema (click, view, lead, sale, refund/chargeback) and make one system the canonical emitter with immutable IDs, timestamps, and versioned attribution rules.
Exit criteria: ≥99.5% of payouts trace to a complete event chain (click→conversion→payout decision); event ID uniqueness = 100%; schema/version changes are logged and reproducible; reconciliation gap between analytics vs payout ledger ≤0.5% of orders.
Issue VCs to affiliates/publishers and internal operators (roles, payout addresses, allowed traffic types). Use VCs to sign submissions and reduce “who are you?” disputes without pretending to solve identity across devices.
Exit criteria: ≥95% of partner actions/events are signed by a valid VC; key rotation + revocation tested end-to-end; onboarding time ≤1 business day; unauthorized/unknown actor events ≤0.1%.
Anchor event batches on-chain (hashes/Merkle roots) to prove “this dataset existed then” and detect tampering, while keeping raw PII off-chain.
Exit criteria: 100% of payout-relevant batches anchored within target window (e.g., ≤15 minutes); independent verifier can reproduce roots from exported logs; PII leakage risk assessment passed; audit can confirm no post-hoc edits without detection.
Route payouts through a single on-chain contract (or a single deterministic settlement service) that consumes the anchored proofs and applies the published payout policy.
Exit criteria: Payout calculation is deterministic and replayable from inputs; payout latency p50 ≤24h and p95 ≤72h (or your business target); contract audited (internal + external) with no critical findings; manual overrides ≤1% of payouts and always logged with reason codes.
Add configurable holding periods, dispute windows, and clawback rules tied to refunds/chargebacks—so the system matches commerce reality without ad-hoc partner penalties.
Exit criteria: Refund/chargeback mapping accuracy ≥99%; clawbacks execute correctly in simulations and live pilots; partner-facing statements show holds/releases clearly; dispute rate on “missing/incorrect clawback” ≤0.5% of affected orders.
Introduce aggregation (daily/weekly Merkle trees, rollups, or batch attestations) to reduce on-chain writes and cost while preserving per-event audit trails off-chain.
Exit criteria: Cost per settled conversion reduced by target (e.g., ≥50%) with no loss of verifiability; auditors can sample any payout and trace it to raw events + batch root; data availability SLA ≥99.9%; reprocessing a day’s batch yields identical outputs.
Add ZKPs to prove policy compliance (e.g., “commission computed correctly,” “partner eligible,” “caps respected”) without revealing sensitive partner rates, user data, or full path details.
Exit criteria: ZKP verification time meets SLA (e.g., p95 ≤2s per proof or per batch); proof failure rate ≤0.1%; privacy review confirms sensitive fields are not exposed; third-party can verify correctness without privileged access.
Deploy detection + response: anomaly thresholds, velocity checks, duplicate patterns, VC revocations, payout throttles, and “pause switches” that are transparent and auditable.
Exit criteria: Mean time to detect (MTTD) suspicious patterns ≤24h; mean time to contain (MTTC) ≤48h; false-positive rate below agreed threshold (e.g., ≤2% of flagged partners); every enforcement action produces an audit record with evidence pointers and appeal workflow.
Boring process, reliable results.
MVP scope: one offer, one conversion event, one payout rule
Limit blast radius. Always.
Success metrics for the MVP:
- payout speed (time from conversion to settlement)
- dispute rate (count + severity)
- reversal rate (and reasons)
- partner comprehension (“can they reproduce the math?”)
ZigPoll’s “smart contract-driven attribution workflows” are a good fit here—encode payout conditions that execute only upon verified credential confirmation (ZigPoll). Trackier’s emphasis on clear attribution policy is the other half of the equation (Trackier).
I’d rather you ship one clean test than ten messy partnerships you can’t explain.
The ‘boring but effective’ checklist: what to document so partners trust the system
Document this like program terms + an audit playbook:
- attribution window + eligible touchpoints (Trackier)
- dedupe rules (what happens when multiple partners touch?)
- payout calculation (rates, tiers, caps)
- refund/chargeback handling (holdbacks, clawbacks)
- what’s on-chain vs off-chain (and why)
- schema versioning + change log policy
- dispute process + time-to-resolution targets
- fraud policy + what triggers review (timestamps help here) (Verifi)
If you disagree, I’m open to it—just show me what you’re measuring.
Measurement: KPIs for transparent attribution (and the ones that will mislead you)
ZigPoll suggests measuring DID/VC issuance rates, payout speed/accuracy, validation rates, and fraud detection rates (ZigPoll). Nielsen reminds us attribution is a measurement technique, not a truth machine (Nielsen).
My operator add-on: separate revenue from incremental revenue. Blockchain won’t do incrementality for you. That still needs experimentation and careful design.
Auditability metrics: dispute rate, time-to-resolution, and ‘can a partner reproduce the math?’
Track:
- dispute rate per 1,000 conversions
- time-to-resolution (median + 90th percentile)
- % of payouts with complete audit trail (touchpoints + credential proof + contract execution)
- partner “math reproducibility” score (yes, qualitative—survey it)
A founder asked me last week why affiliate “works” but still feels like it’s leaking money. Fair question. This is one of the few ways to answer it without vibes.
The win isn’t a spike. The win is a system you can trust next month.
FAQ: the questions people ask right before they ship something risky
Does blockchain solve cross-device attribution?
No. It can help you store and reconcile events, but identity resolution across devices is still hard. Trackier calls out device switching and tracking gaps as a core challenge (Trackier).
Can we be GDPR/CCPA compliant if we use blockchain attribution?
You can design for privacy—ZigPoll points to DIDs, VCs, and ZKPs as privacy-preserving tools (ZigPoll). But compliance is contextual. Talk to counsel. Don’t put PII on a public chain and call it innovation.
What about refunds and chargebacks?
If payouts are automated via smart contracts, you need explicit refund/chargeback logic (holdbacks, escrow, clawbacks). WP Smart Contracts shows instant distribution at deployment time (WP Smart Contracts docs); that’s great when the conversion is final. Many ecommerce conversions aren’t final.
Do we need a token?
Not necessarily. Tokenized incentives are optional. CoinFactory’s affiliate pitch ties commissions to on-chain transactions and pays in crypto (CoinFactory); Qzino’s model is explicitly tokenized profit participation (MEXC / Qzino article). If a token doesn’t improve incentive alignment or auditability, it’s probably noise.
Want help stress-testing your attribution design?
If you’re building blockchain-based transparent affiliate attribution models and you want a second set of eyes, send me:
- your proposed attribution policy (plain English)
- your event schema (click/lead/sale/refund)
- one example conversion path with touchpoints
And I’ll tell you where I think it breaks—before a partner does.
Try it on one offer, one partner type, one traffic source. Then scale what holds up.
Sources
- Trackier — Affiliate Attribution Explained: Models and Key Concepts
- Nielsen — Methods & Models: A Guide to Multi-Touch Attribution
- ZigPoll — Blockchain credentialing for transparent, verifiable affiliate tracking (privacy-preserving)
- Verifi — Blockchain Banking and Fraud Prevention
- WP Smart Contracts — Affiliate Program (docs)
- WP Smart Contracts — Affiliate Program (overview page)
- droplinked — Decentralized affiliate network documentation
- Project Catalyst — Affiso: Decentralized Affiliate System (Status: Not approved)
- CoinFactory — Affiliate program (on-chain transaction transparency claim)
- MEXC — Qzino Affiliate Program: Daily Profit Sharing, Tokenized Rewards, & Lifetime Revenue




