Affiliate Link Tracking Best Practices (2026): UTMs, SubIDs & Server-Side Proof
Affiliate Link Tracking Best Practices (2026): A Boring System You Can Actually Trust
One dashboard says 120 sales, GA4 says 83, the network shows reversals, and nobody can explain which number is “real.”
That’s not a tooling problem. It’s an audit trail problem.
As of 2026-02-09, privacy pressure and browser behavior still mean you should assume tracking loss and design around it, not argue with it. Affiliate spend is big enough that “close enough” gets expensive fast (Impact cites $9.56B US spend in 2023) (impact.com).
This is my practical system for affiliate link tracking best practices: UTMs for analytics, SubIDs for network reporting, and server-side/hybrid when cookies start lying. Fewer unknowns. More trust.
Key Takeaways
- Pick a primary source of truth before you tag anything: network/platform reporting for payouts; analytics (GA4) for on-site behavior and channel mix.
- Standardize parameters: UTMs are for tracking marketing activities in analytics (crakrevenue.com); SubIDs are metadata that comes back in network reports (strackr.com).
- Plan for cookie loss: client-side pixels/cookies are fragile; API/server-to-server (“cookieless”) tracking is positioned as most future-proof and ITP-compliant (impact.com).
- Run tests and keep a change log. Track it. Then verify it.
- Keep tagging and privacy boring: don’t put PII in UTMs/SubIDs; use proper link attributes like
rel="sponsored"/rel="nofollow"(nucleuslinks.ai).
If you only remember one thing: UTMs explain marketing; SubIDs explain money.
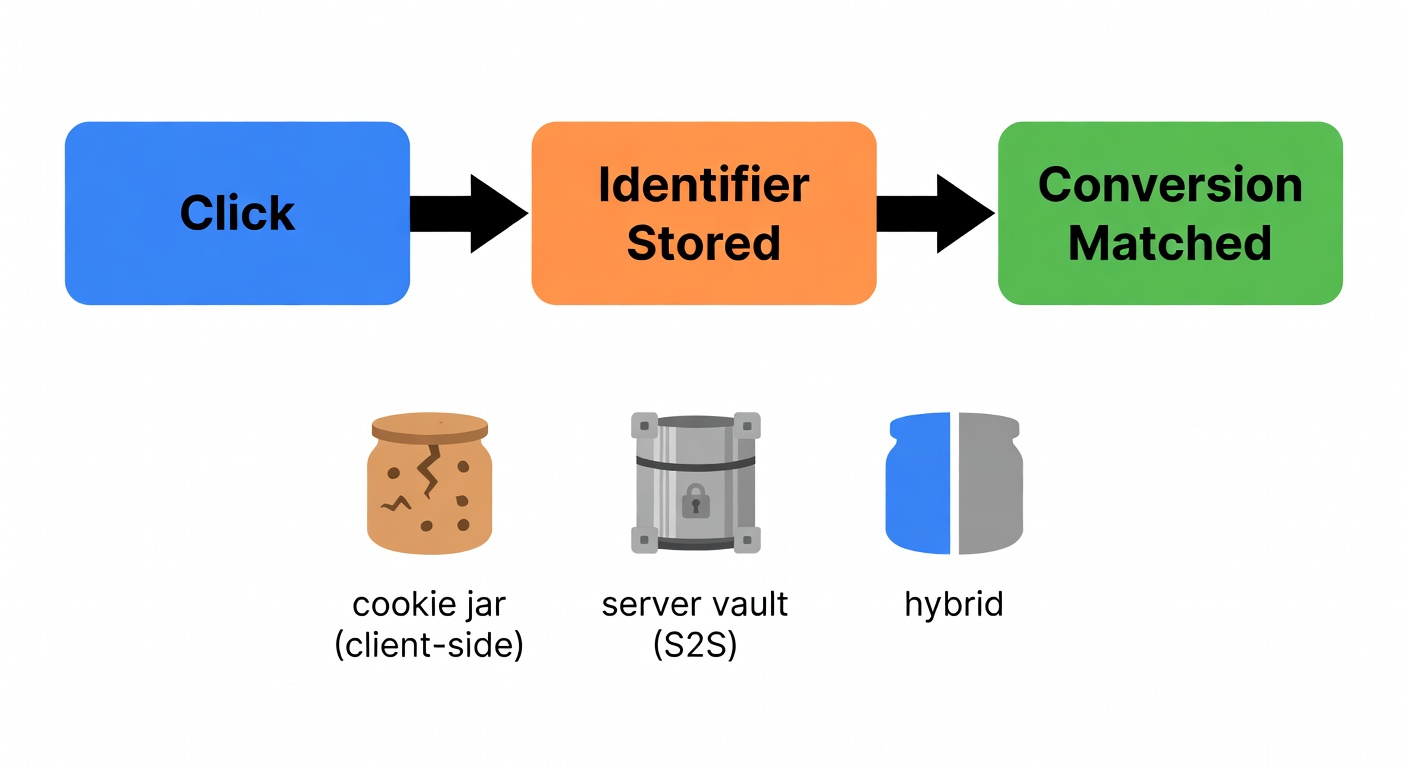
Start Here: What You’re Actually Tracking (and Where It Breaks)
Affiliate tracking is a simple chain:
- A user clicks an affiliate link.
- An identifier gets stored somewhere.
- Later, a conversion event gets matched back to that click.
The problem is step 2. If you can’t explain where the ID lives, you don’t have tracking—just vibes.
Two failure modes show up constantly:
- Cookie loss / browser restrictions. Client-side tracking relies on cookies and a conversion pixel firing in the browser (tune.com). Ad blockers, ITP, and shortened cookie lifetimes punch holes in the chain (stape.io).
- Cross-device and multi-session journeys. People click on mobile, buy on desktop, or come back later. Impact calls out cross-device behavior explicitly (impact.com).
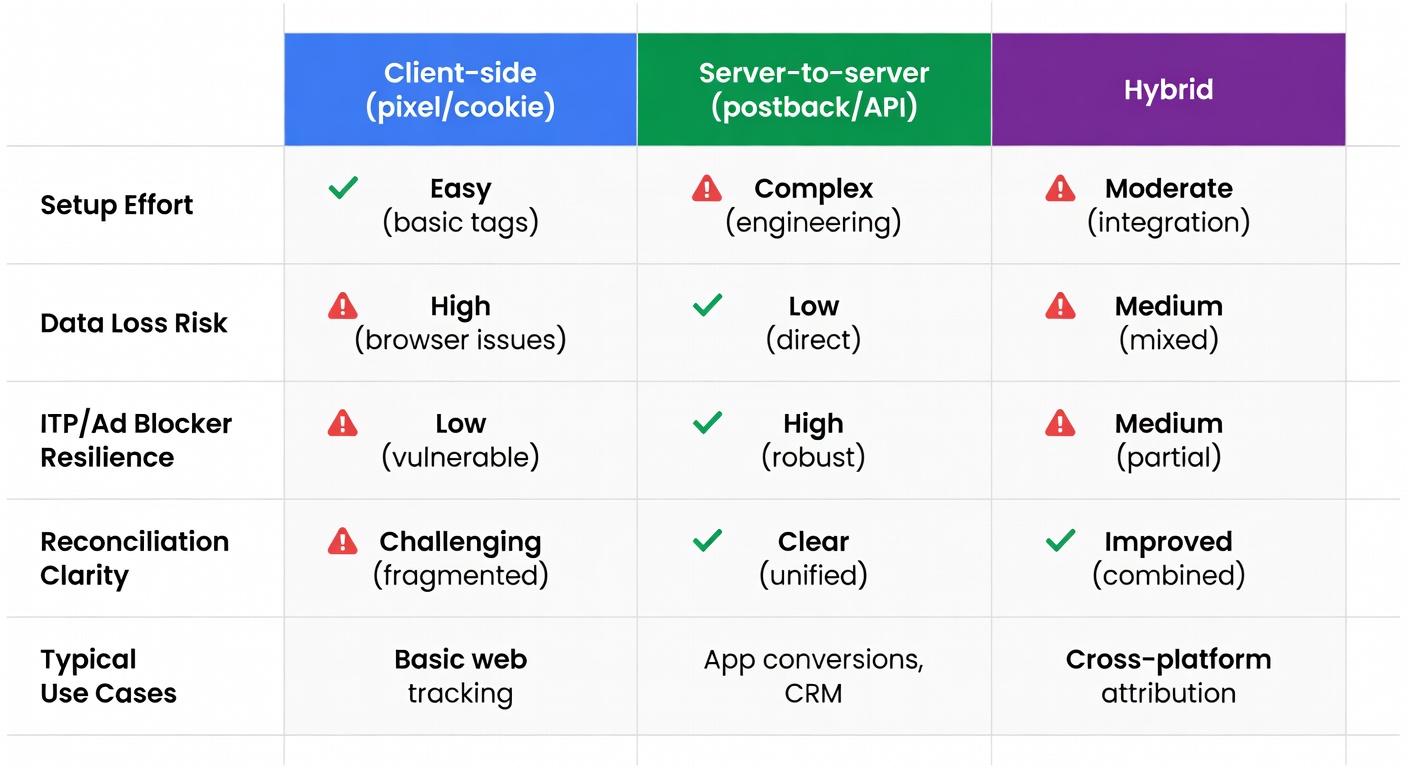
Client-side (pixel/cookie) vs server-to-server: the practical difference
Client-side tracking: the browser stores click info in a cookie; a pixel on the conversion page sends that cookie info back to the platform (tune.com). Easy to ship. Easy to lose.
Server-to-server (S2S): click/conversion info is stored server-side and matched via a unique identifier; the advertiser sends the conversion back via a server postback/API (tune.com). Many consider it more accurate when cookies are disabled (tune.com).
Hybrid is common; Stape explicitly recommends hybrid in some cases rather than going server-side only (stape.io).
The win isn’t “perfect.” The win is “explainable.”
Cookie reality check: Safari ITP, shortened lifetimes, and why ‘first-party’ isn’t magic
Safari’s ITP can block third-party cookie creation; Stape notes that even when a network uses your domain to set cookies (first-party), Safari may still reduce cookie lifetime to one day (stape.io).
Impact’s framing is blunt: API/server-to-server tracking is “cookieless” and “fully compliant with ITP” (impact.com).
Assume loss; design for it.
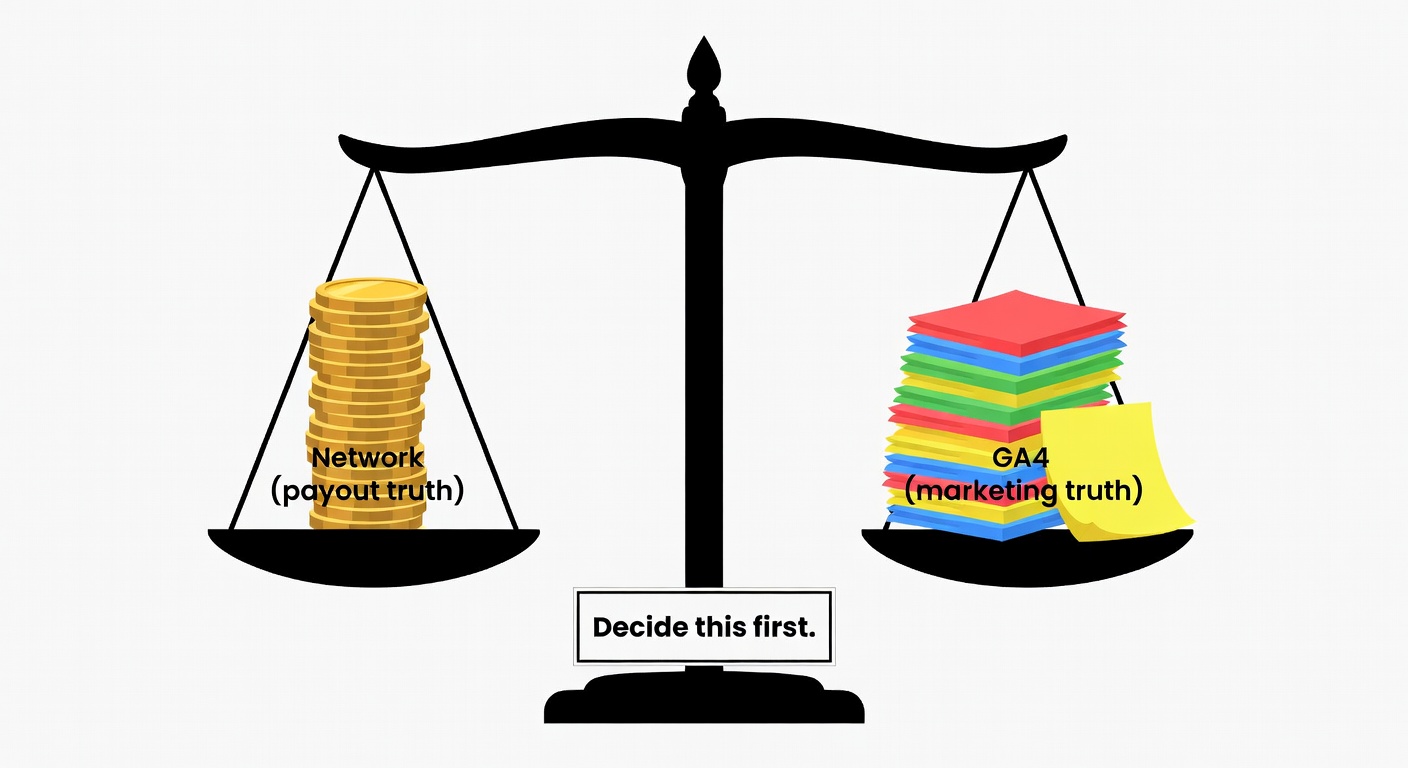
Pick Your ‘Source of Truth’ (or You’ll Argue Forever)
Most teams never decide which system settles disputes. So every month becomes reconciliation theater.
Here’s my hierarchy:
- Network/platform reporting = money truth. If you’re paying commissions, this is what you reconcile against.
- Analytics (GA4) = marketing truth. UTMs exist to track marketing activities and performance in analytics tools like Google Analytics (crakrevenue.com).
UTMs alone aren’t payout-grade. They’re tags on a URL, not a deterministic conversion key.
SubIDs are closer to payout-grade metadata because they’re designed to come back in network reporting as part of the transaction record (strackr.com).
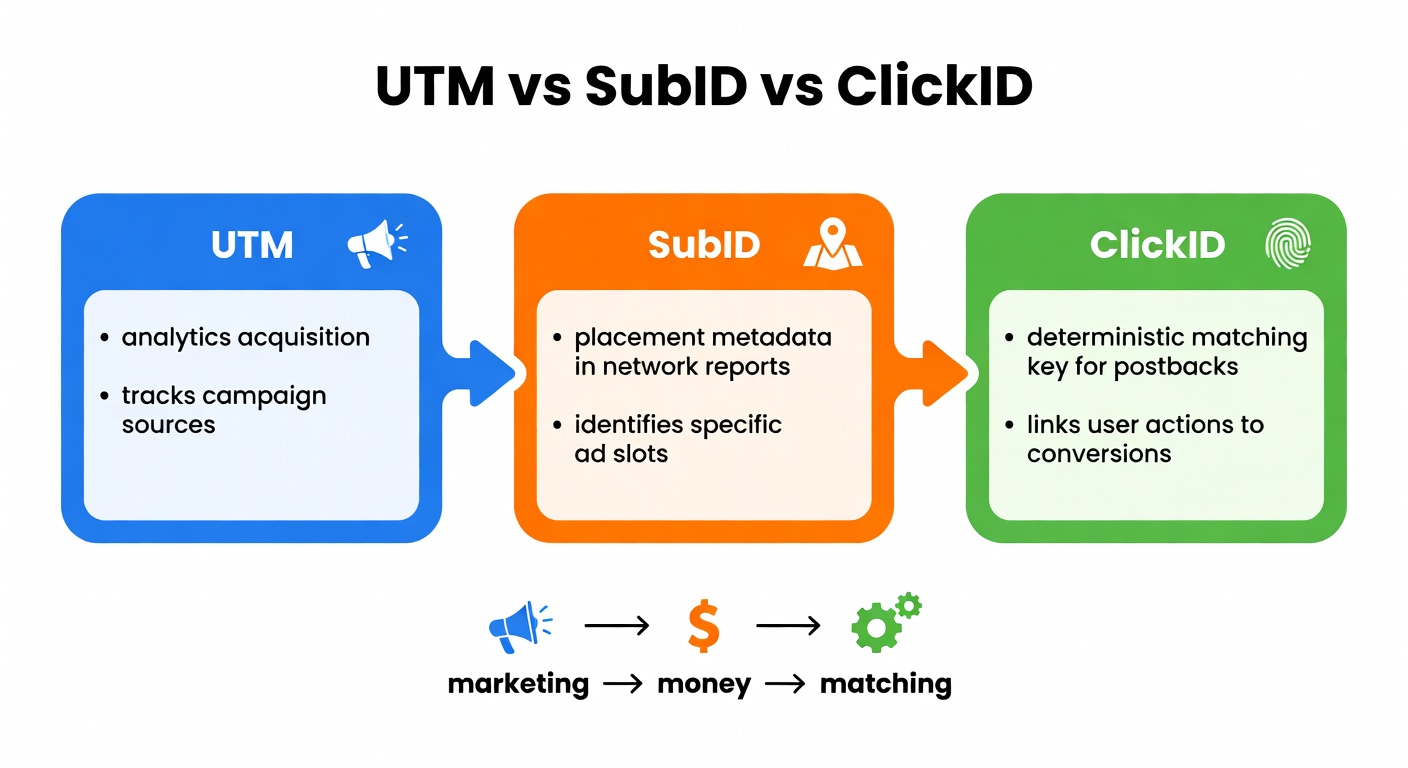
UTM vs SubID vs ClickID: stop using the wrong tool for the job
- UTMs: acquisition reporting in GA4—source/medium/campaign, etc. (crakrevenue.com).
- SubID (SID, afftrack, clickref, etc.): your custom label (placement/page/creative) that shows up in affiliate reports (strackr.com).
- ClickID / transaction_id: the deterministic key used for postbacks and matching conversions (platform-specific, but the concept is consistent).
Network for money, analytics for marketing. That’s the rule.
Parameter Hygiene: A Naming System That Survives Scale (and Humans)
This is where people get burned.
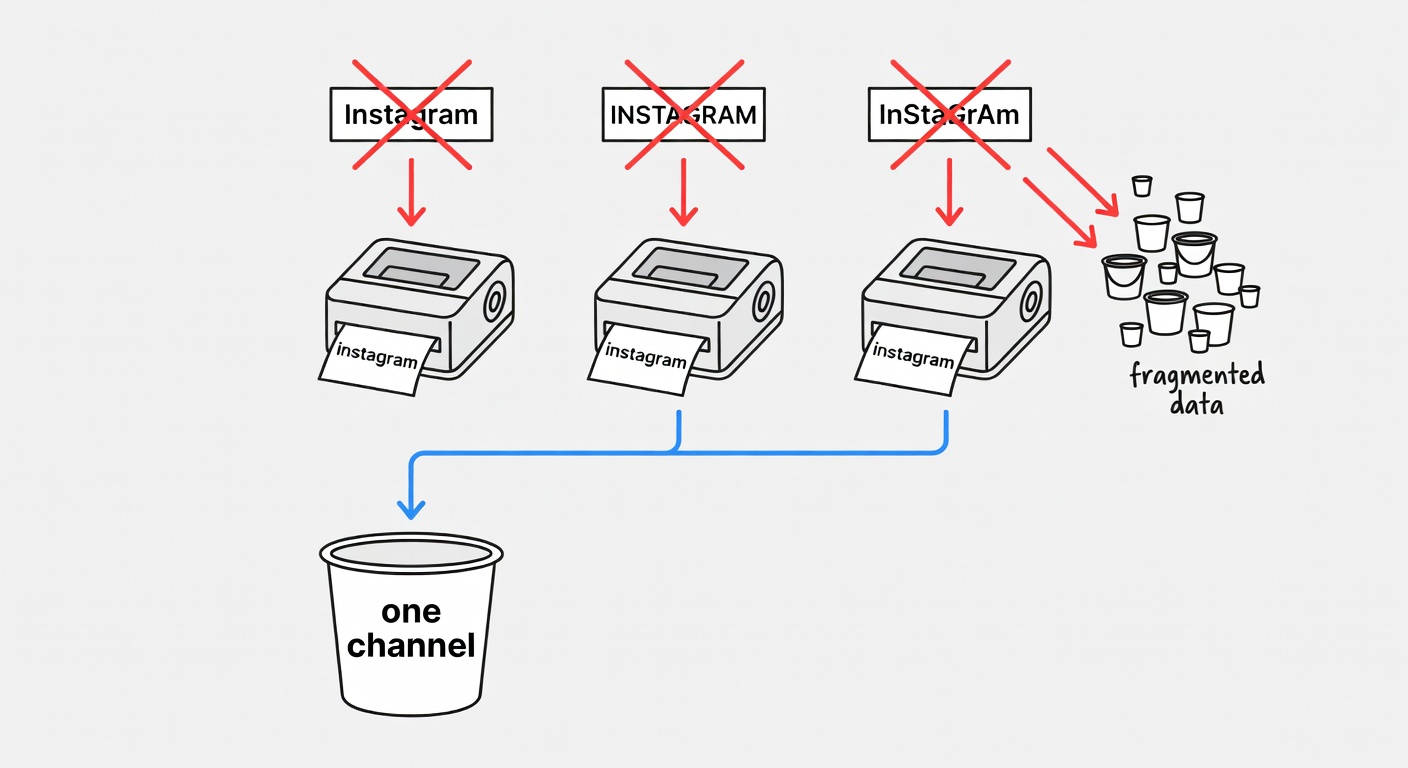
UTMs are case-sensitive; inconsistent capitalization splits your data into fake “new channels” (crakrevenue.com). NucleusLinks calls out the same fragmentation problem (Instagram vs INSTAGRAM vs instagram) (nucleuslinks.ai).
My boring standard:
- lowercase everything
- fixed allowed values for
utm_medium - short campaign names you can read six months later
- SubIDs that encode where the link lived (not who clicked it)
- no PII in UTMs/SubIDs (URLs get copied, logged, and shared)
Bad:
/product?utm_Source=Instagram&utm_medium=Social&utm_campaign=Spring Sale&sid=top banner
Good:
/product?utm_source=instagram&utm_medium=social&utm_campaign=spring_sale&utm_content=story_1&sid=post123_hero_btn
A simple UTM standard (GA4-friendly) you can enforce
Required trio:
utm_source(who sent it)utm_medium(what type of traffic)utm_campaign(what initiative)
Use utm_content to distinguish placements. Use utm_term for paid search keywords.
CTA: publish a one-page UTM dictionary and reject anything off-spec. Annoying. Effective.
A SubID schema for affiliates/publishers (placement, page, creative)
If you only get one field, encode three things:
{page}_{placement}_{creative}
Examples:
best-vpns_table_row1_btnemail_welcome_cta1_textyt_review_pinnedcomment_link
Strackr’s definition is the point: a SubID is a query parameter you attach to track additional data, and it shows up in commission reports (strackr.com). That’s your audit trail.
Future-Proofing: When to Go Server-to-Server (and When Hybrid Is Enough)
A lot of advice screams “go S2S” like it’s a moral stance. I care about resilience.
Go hybrid (client-side + S2S) if:
- you’re mid-volume and don’t want to bet the farm on a new integration
- you need redundancy (because you will ship a broken release eventually)
- you’re seeing some cookie loss but not catastrophic
Go server-to-server if:
- mobile is a big share and Safari performance looks weird
- you’re seeing unexplained conversion drops by browser/device
- you have engineering access (or a vendor) to maintain it
Stape is explicit that Safari ITP can prevent cookie creation and even shorten first-party cookie lifetime; they also say some networks don’t recommend switching exclusively to server-side and that hybrid can be best (stape.io).
Impact positions API tracking as “cookieless” and “most future-proof… fully compliant with ITP” (impact.com).
Example (common pattern): Safari conversions in the network drop ~18% while store orders stay flat. Add hybrid (server-side conversion call + existing pixel). “Missing” conversions mostly reappear, and reversal disputes drop because the click→conversion chain is easier to prove.
Postbacks in plain English: what gets sent, when, and why it fails
A postback URL is the target URL a platform uses to send conversion info to another system (tune.com). Practically: you pass back the click identifier plus optional values like payout/transaction ID.
Failure modes I see most:
- token/macro mismatches
- truncation (IDs cut off)
- sending the conversion before the click is stored (timing bugs)
CTA: write down the exact mapping (click ID in, transaction ID out) in your change log and test with a single conversion before you announce anything to partners.
Audits That Catch Commission Leaks: Broken Links, Vanity Metrics, and Last-Click Gravity
Three leaks show up over and over:
- Broken links / dead deep links. NucleusLinks cites ~66.5% of links on many publisher sites over the last nine years are dead (nucleuslinks.ai). One dead link in a top post is a silent revenue leak.
- Busy metrics. Raw clicks and pageviews make you feel productive. They don’t tell you if you’re making money.
- Last-click gravity. Coupon/loyalty partners tend to show up at checkout and “win” credit. Not always fraud—often misaligned incentives.
Monthly cadence (boring, effective):
- scan for broken affiliate links on top 20 pages
- spot-check top partners’ SubID distribution (are they all “checkout”?)
- reconcile network conversions vs GA4 sessions by campaign (directionally, not perfectly)
Link QA: Catch Broken or Misrouted Affiliate Links Before They Cost You
Here’s the annoying part: you can have pristine UTMs, clean SubIDs, and even S2S postbacks—and still lose money because the outbound link itself is broken, misrouted, or quietly stripped of parameters in a redirect chain.
This is why I treat link QA as part of the audit trail, not “maintenance.” If a link starts 200/OK but ends on the wrong merchant, a geo fallback page, or a dead product page, your reporting gets weird fast: GA4 shows clicks, the network shows nothing, and you end up debugging ghosts.
At scale, manual spot-checking doesn’t hold up (VPN tests are especially good at giving you false confidence). Tools in the automated affiliate link testing/monitoring category can help by validating redirect chains, preserving parameters, and re-testing by geo/device; LinksTest.com is one example of a service positioned for this kind of automated offer/link testing across countries and devices (source, source).
What to test on every affiliate link
The metrics that matter (and the ones that just look busy)
What I track:
- CTR, CVR, AOV, EPC
- funnel drop-offs and device-specific conversion rates
NucleusLinks explicitly warns against vanity metrics like total clicks/impressions/pageviews without correlation to sales (nucleuslinks.ai). Exactly. Measure what changes decisions.
Compliance + Trust: Tagging, Privacy, and Not Getting Cute With Data
Affiliate tracking touches paid relationships and user data. Treat it like a professional channel.
- Link attributes: NucleusLinks summarizes Google’s guidance to tag affiliate links with
rel="sponsored"orrel="nofollow"(nucleuslinks.ai). Pick one policy and enforce it. - Privacy: minimize PII in parameters because URLs get copied, logged, and shared in places you don’t control.
CTA: audit your top 50 affiliate links this week: correct attributes, consistent UTMs, meaningful SubIDs, and zero PII. Then add one line to your change log: “cleaned link hygiene.” The win isn’t a spike. The win is a system you can trust next month.
Sources
- Impact: 6 affiliate tracking methods (+ outcomes of getting it right)
- TUNE: Server-side vs client-side affiliate tracking
- Stape: Server-side affiliate tracking using server GTM (ITP notes + hybrid)
- CrakRevenue: UTM tracking (case sensitivity + GA4 usage)
- Strackr: SubID tracking guide (what SubIDs are + reporting)
- NucleusLinks: Affiliate link tracking tips (dead links + rel attributes + vanity metrics)